Lead4Pass has updated Microsoft DP-100 dumps issues! The latest DP-100 exam questions can help you pass the exam! All questions are corrected to ensure authenticity and effectiveness! Download the Lead4Pass DP-100 VCE dump or PDF dumps: https://www.leads4pass.com/dp-100.html (Total Questions: 218 Q&A DP-100 Dumps)
Exam-Box Exam Table of Contents:
- Latest Microsoft DP-100 google drive
- Effective Microsoft DP-100 Practice testing questions
- Lead4Pass Year-round Discount Code
- What are the advantages of Lead4pass?
Latest Microsoft DP-100 google drive
[PDF] Free Microsoft DP-100 pdf dumps download from Google Drive: https://drive.google.com/file/d/1NyvH6g8U6EVoM_GGGdFTDqSc-NXheNLh/
Latest updates Microsoft DP-100 exam practice questions
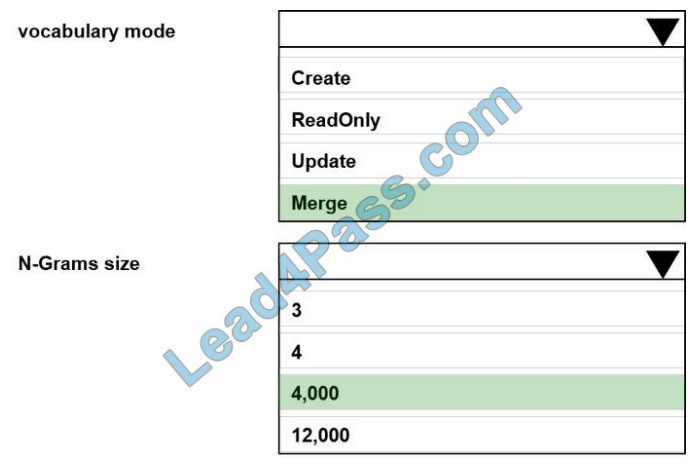
QUESTION 1
HOTSPOT
You are performing sentiment analysis using a CSV file that includes 12.0O0 customer reviews written in a short
sentence format. You add the CSV file to Azure Machine Learning Studio and Configure it as the starting point dataset
of an
experiment. You add the Extract N-Gram Features from the Text module to the experiment to extract key phrases from the
customer review column in the dataset.
You must create a new n-gram text dictionary from the customer review text and set the maximum n-gram size to
trigrams.
You need to configure the Extract N-Gram Features from the Text module.
What should you select? To answer, select the appropriate options in the answer area;
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
QUESTION 2
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than the other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Principal Components Analysis (PCA) sampling mode.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Instead, use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode.
Note: SMOTE is used to increase the number of underrepresented cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
Incorrect Answers:
The Principal Component Analysis module in Azure Machine Learning Studio (classic) is used to reduce the
dimensionality of your training data. The module analyzes your data and creates a reduced feature set that captures all
the
information contained in the dataset, but in a smaller number of features.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/principal-component-analysis
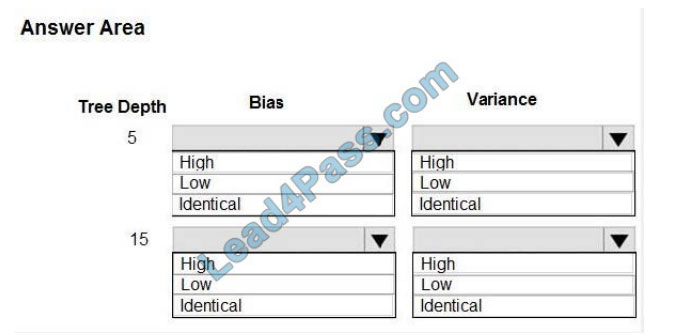
QUESTION 3
You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to 10.
You need to select the bias and variance properties of the model with varying tree depth values.
Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area.
Hot Area:
Correct Answer:
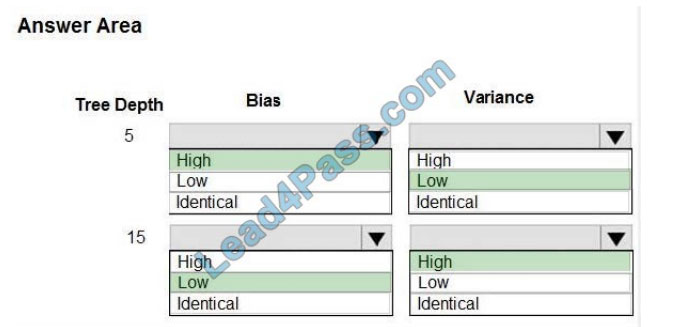
Indecision trees, the depth of the tree determines the variance. A complicated decision tree (e.g. deep) has low bias
and high variance.
Note: In statistics and machine learning, the bias-variance tradeoff is the property of a set of predictive models whereby
models with a lower bias in parameter estimation have a higher variance of the parameter estimates across samples
and vice versa. Increasing the bias will decrease the variance. Increasing the variance will decrease bias.
References: https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning/
QUESTION 4
You are building a recurrent neural network to perform binary classification.
The training loss, validation loss, training accuracy, and validation accuracy of each training epoch has been provided.
You need to identify whether the classification model is overfitted.
Which of the following is correct?
A. The training loss stays constant and the validation loss stays on a constant value and closes to the training loss value
when training the model.
B. The training loss decreases while the validation loss increases when training the model.
C. The training loss stays constant and the validation loss decreases when training the model.
D. The training loss increases while the validation loss decreases when training the model.
Correct Answer: B
An overfit model is one where performance on the train set is good and continues to improve, whereas performance on
the validation set improves to a point and then begins to degrade. References: https://machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/
QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than the other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
SMOTE is used to increase the number of underrepresented cases in a dataset used for machine learning. SMOTE is a
better way of increasing the number of rare cases than simply duplicating existing cases.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
QUESTION 6
DRAG DROP
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions
to the answer area and arrange them in the correct order.
Select and Place: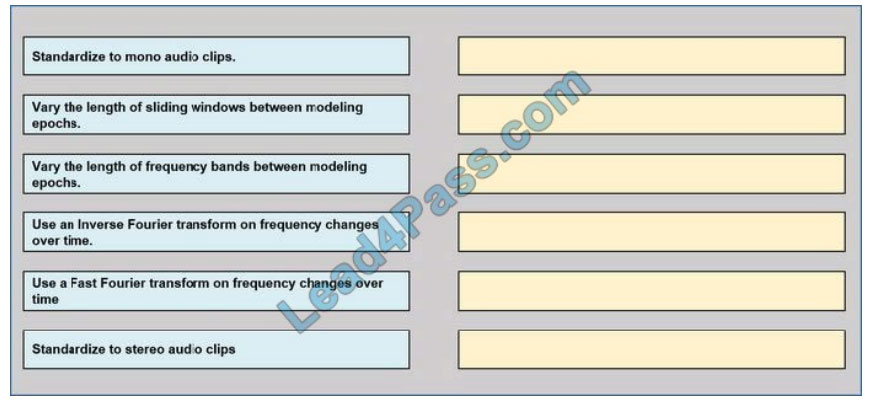
Correct Answer:
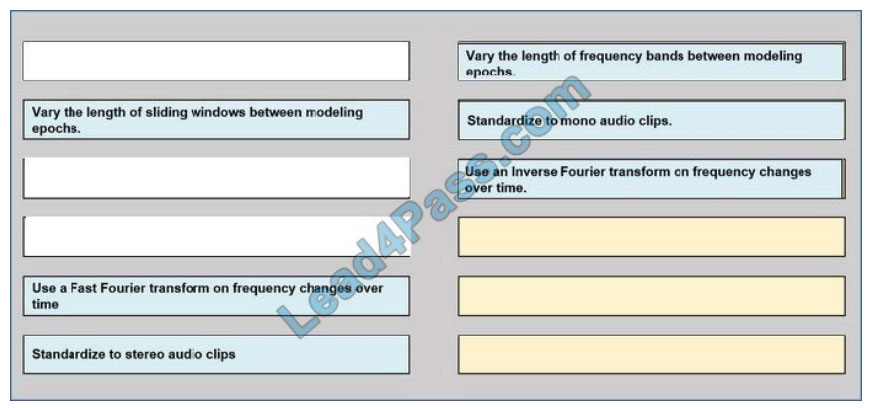
QUESTION 7
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen. You are analyzing a numerical dataset that contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature
set.
You need to analyze a full dataset to include all values.
Solution: Remove the entire column that contains the missing data point.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Use the Multiple Imputation by Chained Equations (MICE) method.
References:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
QUESTION 8
You are evaluating a completed binary classification machine learning model.
You need to use the precision as the evaluation metric.
Which visualization should you use?
A. Violin pilot
B. Gradient descent
C. Box pilot
D. Binary classification confusion matrix
Correct Answer: D
Incorrect Answers:
A: A violin plot is a visual that traditionally combines a box plot and a kernel density plot.
B: Gradient descent is a first-order iterative optimization algorithm for finding the minimum of a function. To find a local
minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient (or
approximate gradient) of the function at the current point.
C: A box plot lets you see basic distribution information about your data, such as median, mean, range, and quartiles but
doesn\\’t show you how your data looks throughout its range.
References: https://machinelearningknowledge.ai/confusion-matrix-and-performance-metrics-machine-learning/
QUESTION 9
HOTSPOT
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Box 1: 500
For Random seed, type a value to use as seed for randomization. If you specify 0 (the default), a number is generated
based on the system clock.
A seed value is optional, but you should provide a value if you want reproducibility across runs of the same experiment.
Here we must replicate the findings.
Box 2: Mean Absolute Error
Scenario: Given a trained model and a test dataset, you must compute the Permutation Feature Importance scores of
feature variables. You need to set up the Permutation Feature Importance module to select the correct metric to
investigate
the model\\’s accuracy and replicate the findings.
Regression. Choose one of the following: Precision, Recall, Mean Absolute Error, Root Mean Squared Error, Relative
Absolute Error, Relative Squared Error, Coefficient of Determination
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/permutation-feature-importance
QUESTION 10
You have a feature set containing the following numerical features: X, Y, and Z.
The Poisson correlation coefficient (r-value) of X, Y, and Z features is shown in the following image:

Use the drop-down menus to select the answer choice that answers each question based on the information presented
in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: 0.859122
Box 2: a positively linear relationship +1 indicates a strong positive linear relationship -1 indicates a strong negative
linear correlation 0 denotes no linear relationship between the two variables. References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-linear-correlation
QUESTION 11
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:
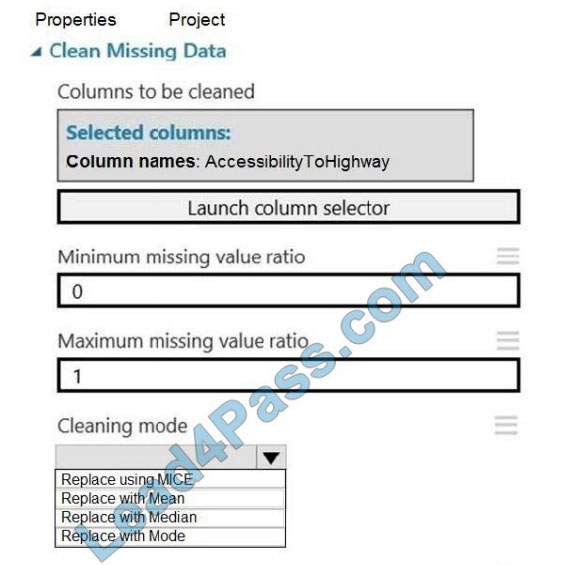

Correct Answer:
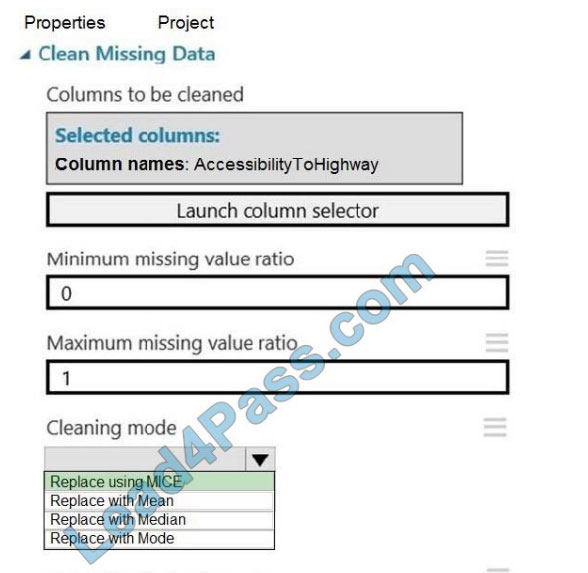
Box 1: Replace using MICE
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method
described in the statistical literature as “Multivariate Imputation using Chained Equations” or “Multiple Imputation by
Chained Equations”. With a multiple imputation method, each variable with missing data is modeled conditionally using
the other variables in the data before filling in the missing values.
Scenario: The AccessibilityToHighway column in both datasets contains missing values. The missing data must be
replaced with new data so that it is modeled conditionally using the other variables in the data before filling in the
missing
values.
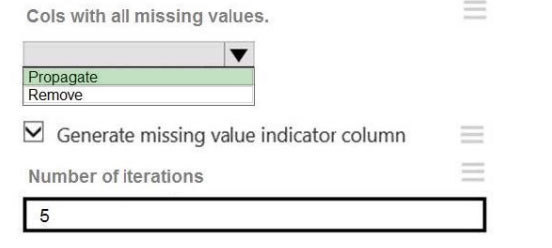
Box 2: Propagate
Cols with all missing values indicate if columns of all missing values should be preserved in the output.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
QUESTION 12
HOTSPOT
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Scenario: Testing
You must produce multiple partitions of a dataset based on sampling using the Partition and Sample module in Azure
Machine Learning Studio.
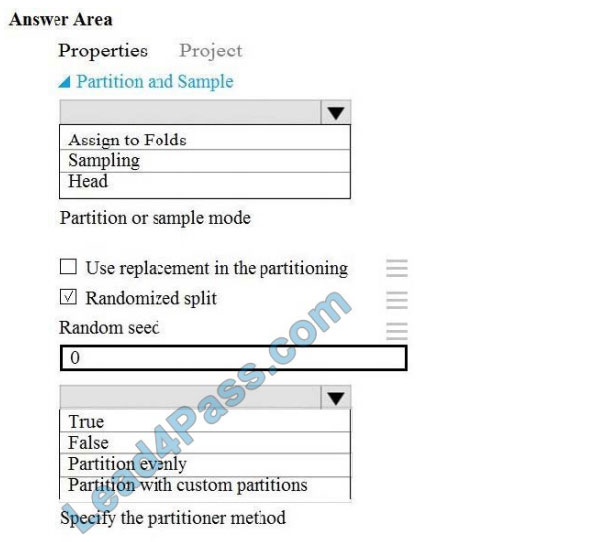
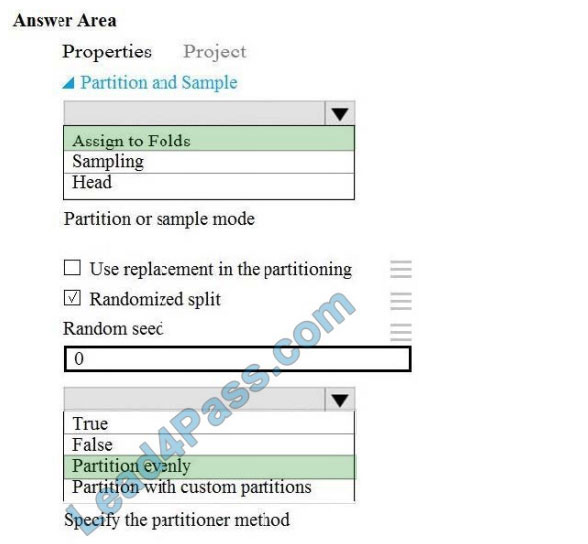
Box 1: Assign to folds
Use Assign to folds option when you want to divide the dataset into subsets of the data. This option is also useful when
you want to create a custom number of folds for cross-validation, or to split rows into several groups.
Not Head: Use Head mode to get only the first n rows. This option is useful if you want to test a pipeline on a small
a number of rows and don\\’t need the data to be balanced or sampled in any way.
Not Sampling: The Sampling option supports simple random sampling or stratified random sampling. This is useful if
you want to create a smaller representative sample dataset for testing.
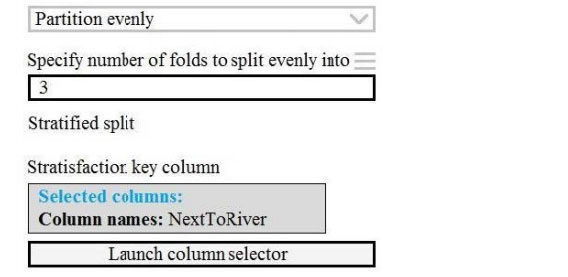
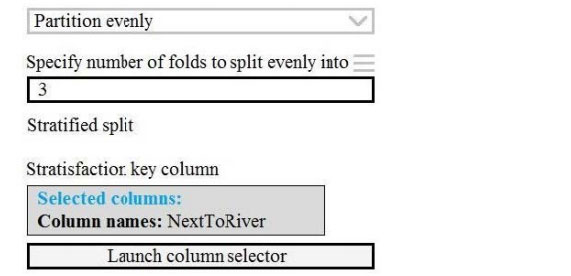
Box 2: Partition evenly
Specify the partitioner method: Indicate how you want data to be apportioned to each partition, using these options:
Partition evenly: Use this option to place an equal number of rows in each partition. To specify the number of output
partitions, type a whole number in the Specify number of folds to split evenly into the text box.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/partition-and-sample
QUESTION 13
You are using the C-Support Vector classification to do a multi-class classification with an unbalanced training dataset. The
C-Support Vector classification using Python code shown below:

You need to evaluate the C-Support Vector classification code.
Which evaluation statement should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
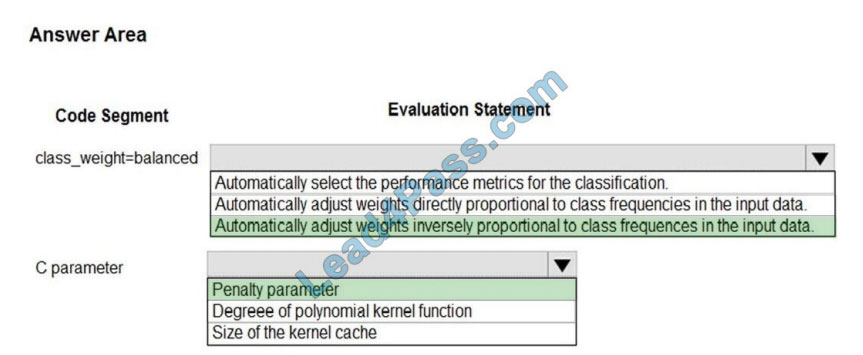
Box 1: Automatically adjust weights inversely proportional to class frequencies in the input data
The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in
the input data as n_samples / (n_classes * np.bincount(y)).
Box 2: Penalty parameter
Parameter: C : float, optional (default=1.0)
Penalty parameter C of the error term.
References:
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
Latest Lead4Pass Microsoft dumps Discount Code 2020

About The Lead4Pass Dumps Advantage
Lead4Pass has 7 years of exam experience! A number of professional Microsoft exam experts! Update exam questions throughout the year! The most complete exam questions and answers! The safest buying experience! The greatest free sharing of exam practice questions and answers!
Our goal is to help more people pass the Microsoft exam! Exams are a part of life, but they are important!
In the study you need to sum up the study! Trust Lead4Pass to help you pass the exam 100%!
Summarize:
This blog shares the latest Microsoft DP-100 exam dumps, DP-100 exam questions, and answers! DP-100 pdf, DP-100 exam video!
You can also practice the test online! Lead4pass is the industry leader!
Select Lead4Pass DP-100 exams Pass Microsoft DP-100 exams “Designing and Implementing a Data Science Solution on Azure”.
Help you successfully pass the DP-100 exam.
ps.
Get Microsoft Full Series Exam Dump: https://www.fulldumps.com/?s=Microsoft (Updated daily)
Get Lead4Pass Azure Data Scientist Associate exam dumps: https://www.leads4pass.com/role-based.html
Latest update Lead4pass DP-100 exam dumps: https://www.leads4pass.com/dp-100.html (218 Q&As)
[Q1-Q12 PDF] Free Microsoft DP-100 pdf dumps download from Google Drive: https://drive.google.com/file/d/1NyvH6g8U6EVoM_GGGdFTDqSc-NXheNLh/